Model Parameters
Overview
Model parameters are the key settings that control how AI models generate responses. By fine-tuning these parameters, you can optimize the model’s behavior for your specific use case, whether you need creative writing, factual analysis, or conversational interactions.
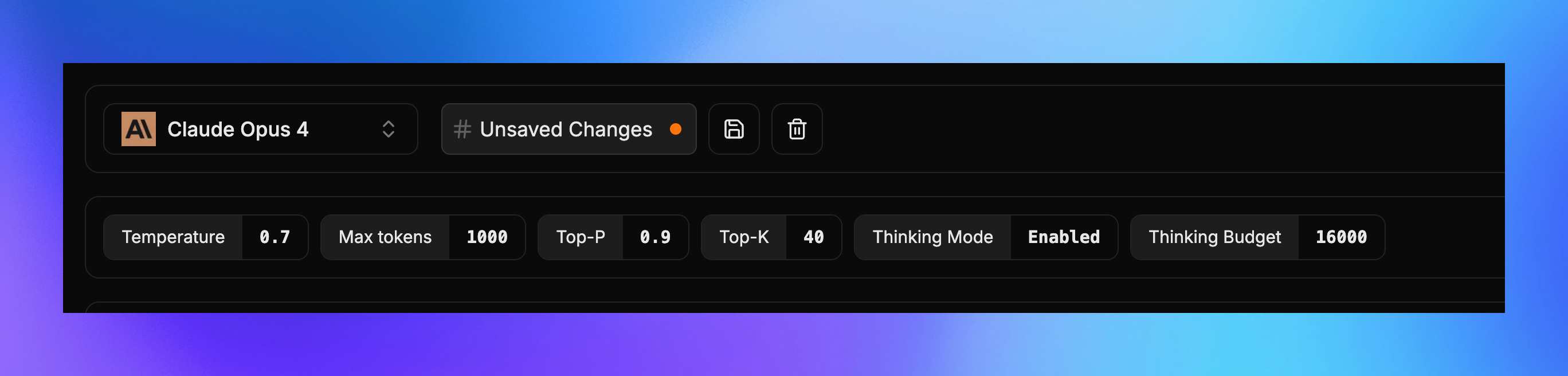
Core Parameters
Temperature
Controls the randomness and creativity of the model’s responses.
- Range: 0.0 - 2.0
- How it works: Lower values make responses more focused and deterministic, while higher values increase creativity and randomness
- Use cases:
- 0.0-0.3: Factual responses, code generation, data analysis
- 0.4-0.7: Balanced responses, general conversation
- 0.8-2.0: Creative writing, brainstorming, varied outputs
Max Tokens
Sets the maximum length of the model’s response.
- Purpose: Controls response length and API costs
- Considerations:
- Each model has different token limits
- Longer responses cost more
- Balance between completeness and efficiency
- Tips: Start with 1000-2000 tokens for most use cases
Top P (Nucleus Sampling)
Controls the diversity of token selection by considering only the most likely tokens.
- Range: 0.0 - 1.0
- Default: 1.0
- How it works: Lower values focus on more probable tokens, higher values allow more diverse choices
- Interaction with Temperature: Often used together to fine-tune response quality
Frequency Penalty
Reduces repetition in the model’s responses.
- Range: -2.0 to 2.0
- Positive values: Decrease repetition (recommended: 0.1-1.0)
- Negative values: Increase repetition
- Best for: Long-form content, creative writing
Presence Penalty
Encourages the model to introduce new topics and concepts.
- Range: -2.0 to 2.0
- Positive values: Introduce new topics (recommended: 0.1-1.0)
- Negative values: Stay focused on existing topics
- Best for: Exploratory conversations, brainstorming
Reasoning Parameters
Advanced reasoning parameters control how models think through complex problems before generating responses.
OpenAI Models
- Reasoning Effort: Controls how much computational effort the model puts into reasoning (Low/Medium/High)
- Reasoning Summary: Determines whether to include reasoning steps in the response
Anthropic Claude
- Thinking Mode: Enables step-by-step reasoning process (Auto/Manual)
- Thinking Budget: Sets maximum tokens allocated for internal reasoning
Google AI (Gemini)
- Enable Thinking: Activates internal reasoning process
- Thinking Budget: Controls computational resources for reasoning
xAI (Grok)
- Reasoning Effort: Adjusts reasoning depth and complexity
- Grok-4: Automatically enables thinking mode (not configurable)
Provider Documentation
For detailed parameter specifications and advanced features:
- OpenAI: API Reference
- Anthropic: Claude API Documentation
- Google AI: Gemini API Guide
- xAI: Grok API Documentation
Last updated on